
ChatGPT is OpenAI's first public introduction to chat based AI. By now most people have heard of it and even used it. It has enabled every day users to have access to bleeding edge artificial intellegence. You can even use it for free! To use their latest models, you will need to pay $20 a month for a subscription.
ChatGPT isn't the only game in town though, open source projects have been closing the gap between big business funded AI and community developed AI. As I said in my previous post, I actually run a lot of modesl locally on my machine. This post will go into detail on how you can do this as well. Keep in mind, for good performance you will need a decent GPU, the faster the better. A lot of these models will run on CPU, but they will be a lot slower to respond and process your requests.
Introducing Ollama
Ollama is the easiest way to get into running community provided AI models. In fact, it is so easy, I can tell you how to do it in two lines.
- curl https://ollama.ai/install.sh | sh
- ollama run llama2
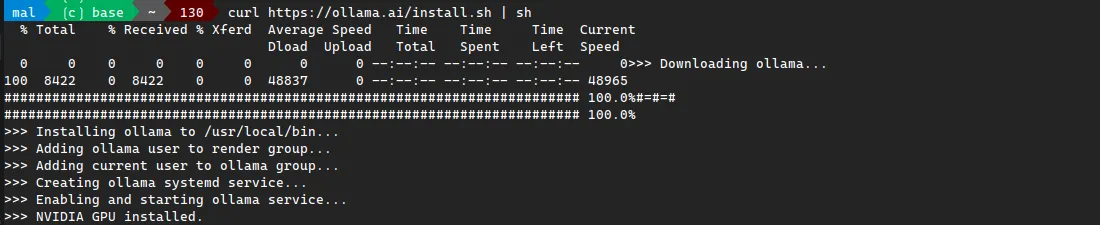

That's it, you are now running the latest version of the Llama2 AI model locally on your machine.
This is running the Llama2 model, which has a lot of restrictions and isn't very good. There are a lot better models, and some are for specific purposes. Let's check them out.
If you head over to https://ollama.ai/library, you can find a list of the models supported by Ollama. You are not limited to these models, but these have been tested.
One I recommend checking out is Mistral OpenOrca, this is a great model that is really small and will run on most GPUs without a problem.
After pulling the model with ollama run mistral-openorca you will be left at a chat prompt.
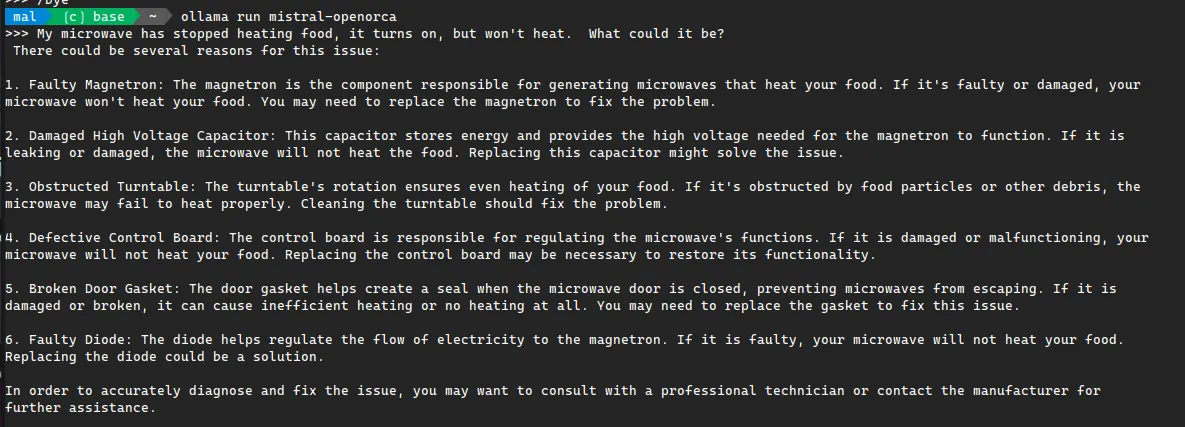
One thing you might want to do, is see how well a model is performing on your machine. If you type /set verbose you will get a summary at the end of your requests.
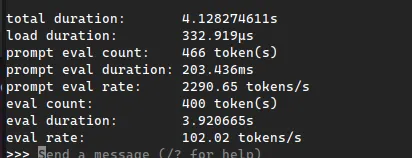
With an nVidia 3090 I tend to get a little over 100 tokens per second. This is faster than a typical user can read, and is a very acceptable speed. Most models have 7 billion parameters, these typically require around 8GB of VRAM to run. 33 billion is usually the next class of model and will require at least 16GB or more of VRAM.
Using a 33 billion parameter model on my nVidia 3090 I am looking at around 30-33 tokens/second. This is a lot slower, still usable and pretty close to what a human can read.
total duration: 14.078252008s
load duration: 682.399µs
prompt eval count: 357 token(s)
prompt eval duration: 677.234ms
prompt eval rate: 527.14 tokens/s
eval count: 408 token(s)
eval duration: 13.398543s
eval rate: 30.45 tokens/s
From here, the next step would be using a 70 billion parameter model, but on a single nVidia 3090 with only 24G of ram, this isn't doable. There are ways to do this with system ram, and even a mix of VRAM and system ram, and even CPU only. So in theory, I could get it working, but performance would be awful. This is where dedicated cards for AI are critical to using larger models. The cost for these cards goes up expontially, many starting at around $10,000 and those only have around 40GB of ram.
There is another aspect of open source models I didn't mention, this is training and fine tuning. You can take existing models and tune them to domains you are interested in. Let's say you are doctor, and you want to use AI to assist you in diagnosing patients. You can fine tune a model to review hundreds, thousands, and even millions of books and documents to learn your specific industry. This will perform better for this use case than other models, even ChatGPT if done correctly. This process though is extremely expensive and hardware dependent.
Companies are buying up hundreds of thousands of GPUS to do this. For example, Meta has disclosed they are looking to buy 350,000 H100 GPUs priced at around $30,000. This will double their current AI infrastructure.
Tools like Ollama and LM Studio allow anyone to install and run models on their own machines. Many of these models have distinct advantages over other commerical models. To really take advantage of these models though, you will need to learn how well they perform to your prompts and potentially tailor them to the specific model to get good results.
Some models punch well above their weight class, like Mistral, but some you will easily tell it's a small model and will have difficulty getting results similar to chatGPT and larger models. Some models can come close to or exceed ChatGPT 3.5 Turbo (default ChatGPT model) but nothing you can download can really compete with ChatGPT 4 at this point. It is a massive model with lots of training, but the gap is closing quickly.
Google recently wrote an article commonly referred to as "There is no moat". In this article, Google goes on to say they have no "secret sauce", nor does Open AI, that will protect them from the open source community surpassing them. It won't be any time soon, but it is very likely one day. If this interests you, I highly recommend you read the article.